LLM Application Tracing
LLM applications use increasingly complex abstractions, such as chains, agents with tools, and advanced prompts. The nested traces in Langfuse help to understand what is happening and identify the root cause of problems.
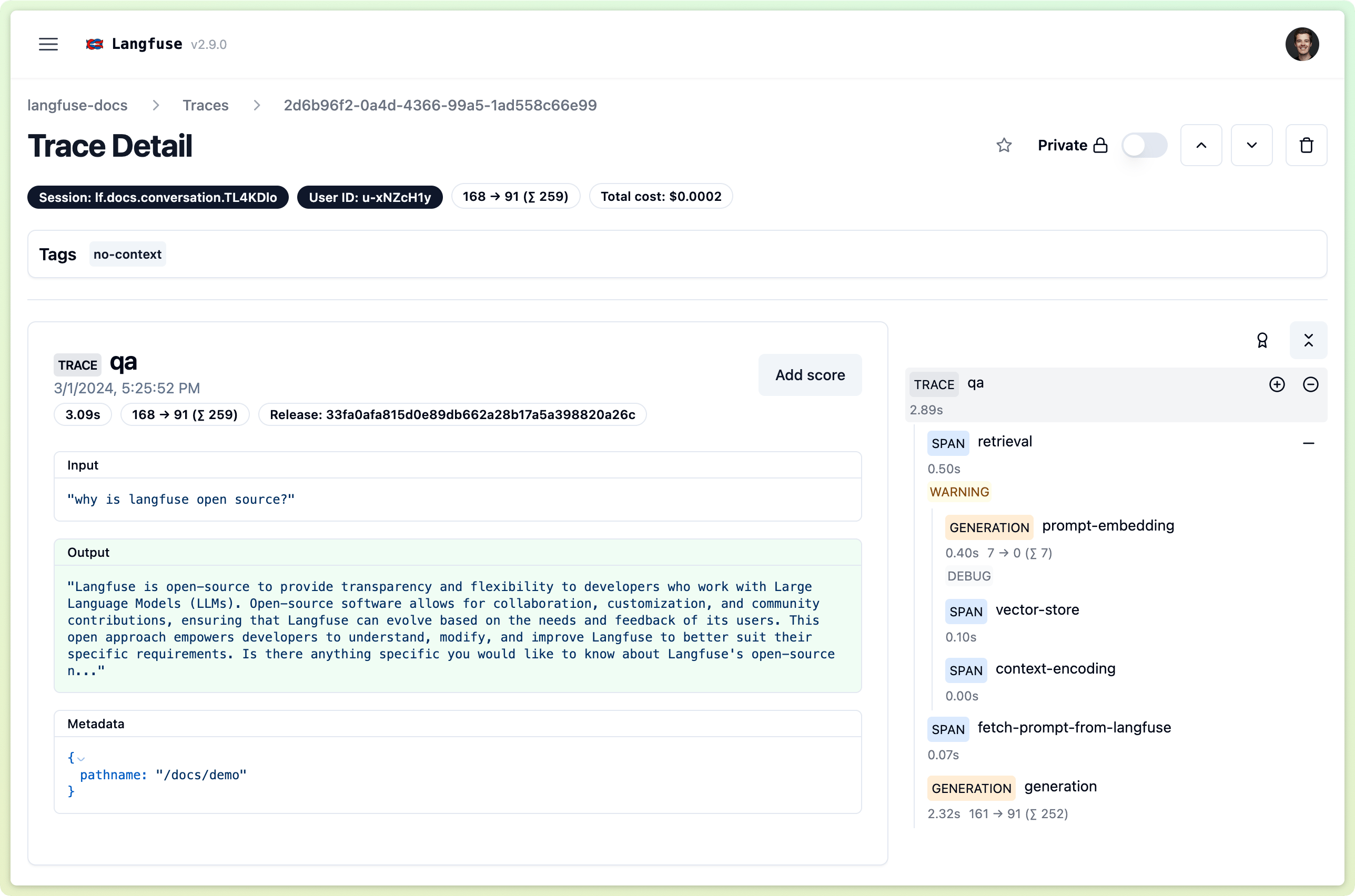 Example trace of our public demo
Example trace of our public demo
Why Use Tracing for an LLM Application?
- Capture the full context of the execution, including API calls, context, prompts, parallelism, and more
- Track model usage and cost
- Collect user feedback
- Identify low-quality outputs
- Build fine-tuning and testing datasets
Why Langfuse?
- Open-source
- Low performance overhead
- SDKs for Python and JavaScript
- Integrated with popular frameworks: OpenAI SDK (Python), Langchain (Python, JS), LlamaIndex (Python)
- Public API for custom integrations
- Suite of tools for the whole LLM application development lifecycle
Introduction to Traces in Langfuse
A trace in Langfuse consists of the following objects:
- A
tracetypically represents a single request or operation. It contains the overall input and output of the function, as well as metadata about the request, such as the user, the session, and tags. - Each trace can contain multiple
observationsto log the individual steps of the execution.- Observations are of different types:
Eventsare the basic building blocks. They are used to track discrete events in a trace.Spansrepresent durations of units of work in a trace.Generationsare spans used to log generations of AI models. They contain additional attributes about the model, the prompt, and the completion. For generations, token usage and costs are automatically calculated.
- Observations can be nested.
- Observations are of different types:
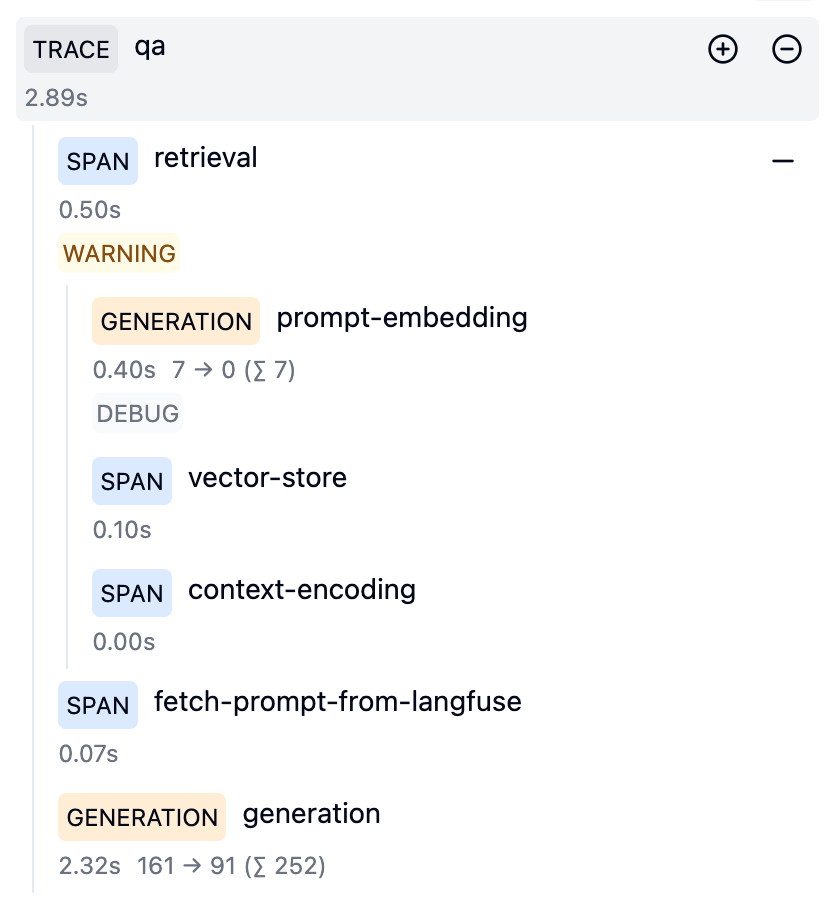
Hierarchical structure of traces in Langfuse
Example trace in Langfuse UI
We're sorry, no dark mode yet 🕶️
Get Started
Follow the quickstart to add Langfuse tracing to your LLM app.
Advanced usage
You can extend the tracing capabilities of Langfuse by using the following features:
Event queuing/batching
Langfuse's client SDKs and integrations are all designed to queue and batch requests in the background to optimize API calls and network time. Batches are determined by a combination of time and size (number of events and size of batch).
Configuration
All integrations have a sensible default configuration, but you can customise the batching behaviour to suit your needs.
| Option (Python) | Option (JS) | Description |
|---|---|---|
flush_at | flushAt | The maximum number of events to batch up before sending. |
flush_interval (s) | flushInterval (ms) | The maximum time to wait before sending a batch. |
You can e.g. set flushAt=1 to send every event immediately, or flushInterval=1000 to send every second.
Manual flushing
This is especially relevant for short-lived applications like serverless functions. If you do not flush the client, you may lose events.
If you want to send a batch immediately, you can call the flush method on the client. In case of network issues, flush will log an error and retry the batch, it will never throw an exception.
# Decorator
from langfuse.decorators import langfuse_context
langfuse_context.flush()
# low-level SDK
langfuse.flush()If you exit the application, use shutdown method to make sure all requests are flushed and pending requests are awaited before the process exits. On success of this function, no more events will be sent to Langfuse API.
langfuse.shutdown()