Prompt Management
Use Langfuse to effectively manage and version your prompts. Langfuse prompt management is basically a Prompt CMS (Content Management System).
Why use prompt management?
Can't I just hardcode my prompts in my application and track them in Git? Yes, well... you can and all of us have done it.
Typical benefits of using a CMS apply here:
- Decoupling: deploy new prompts without redeploying your application.
- Non-technical users can create and update prompts via Langfuse Console.
- Quickly rollback to a previous version of a prompt.
Platform benefits:
- Track performance of prompt versions in Langfuse Tracing.
Langfuse prompt object
{
"name": "movie-critic",
"type": "text",
"prompt": "Do you like {{movie}}?",
"config": {
"model": "gpt-3.5-turbo",
"temperature": 0.5,
"supported_languages": ["en", "fr"]
},
"version": 1,
"is_active": true
}name: Unique name of the prompt within a Langfuse project.type: The type of the prompt content (textorchat). Default istext.prompt: The text template with variables (e.g.This is a prompt with a {{variable}}). For chat prompts, this is a list of chat messages each withroleandcontent.config: Optional JSON object to store any parameters (e.g. model parameters or model tools).version: Integer to indicate the version of the prompt. The version is automatically incremented when creating a new prompt version.is_active: Boolean to indicate if the prompt version is in production. This is the default version that is returned when fetching the prompt by name.
How it works
Create/update prompt
If you already have a prompt with the same name, the prompt will be added as a new version.
Use prompt
At runtime, you can fetch the latest production version from Langfuse.
from langfuse import Langfuse
# Initialize Langfuse client
langfuse = Langfuse()
# Get current production version of a text prompt
prompt = langfuse.get_prompt("movie-critic")
# Insert variables into prompt template
compiled_prompt = prompt.compile(movie="Dune 2")
# -> "Do you like Dune 2?"Chat prompts
# Get current production version of a chat prompt
chat_prompt = langfuse.get_prompt("movie-critic-chat", type="chat") # type arg infers the prompt type (default is 'text')
# Insert variables into chat prompt template
compiled_chat_prompt = chat_prompt.compile(movie="Dune 2")
# -> [{"role": "system", "content": "You are an expert on Dune 2"}]Optional parameters
# Get specific version
prompt = langfuse.get_prompt("movie-critic", version=1)
# Extend cache TTL from default 60 to 300 seconds
prompt = langfuse.get_prompt("movie-critic", cache_ttl_seconds=300)Attributes
# Raw prompt including {{variables}}. For chat prompts, this is a list of chat messages.
prompt.prompt
# Config object
prompt.configLink with Langfuse Tracing (optional)
Add the prompt object to the generation call in the SDKs to link the generation in Langfuse Tracing to the prompt version. This allows you to track metrics by movie-critic and version in the Langfuse UI.
This is currently unavailable when using the LangChain or LlamaIndex integration.
Decorators
from langfuse.decorators import langfuse_context, observe
@observe(as_type="generation")
def nested_generation():
prompt = langfuse.get_prompt("movie-critic")
langfuse_context.update_current_observation(
prompt=prompt,
)
@observe()
def main():
nested_generation()
main()Low-level SDK
langfuse.generation(
...
+ prompt=prompt
...
)Rollbacks (optional)
Set a prompt version to active when creating it via the SDKs. In the Langfuse UI, you can promote a specific prompt version to quickly rollback:
End-to-end examples
The following example notebooks include end-to-end examples of prompt management:
We also used Prompt Management for our Docs Q&A Chatbot and traced it with Langfuse. You can get view-only access to the project by signing up to the public demo.
Performance
Caching in client SDKs
While Langfuse Tracing is fully asynchronous and non-blocking, managing prompts in Langfuse adds latency to your application when retrieving the prompt. To minimize the impact on your application, prompts are cached in the client SDKs. The default cache TTL is 60 seconds and is configurable.
When refetching a prompt fails but an expired version is in the cache, the SDKs will return the expired version, preventing application blockage due to network issues.
# Get current production prompt version and cache for 5 minutes
prompt = langfuse.get_prompt("movie-critic", cache_ttl_seconds=300)
# Disable caching for a prompt
prompt = langfuse.get_prompt("movie-critic", cache_ttl_seconds=0)Performance measurement (excluding cache hits)
We measured the execution time of the following snippet. We disabled the cache to measure the performance of the prompt retrieval and compilation.
prompt = langfuse.get_prompt("perf-test", cache_ttl_seconds=0) # disable cache
prompt.compile(input="test")Results from 1000 sequential executions in a local jupyter notebook using Langfuse Cloud (includes network latency):
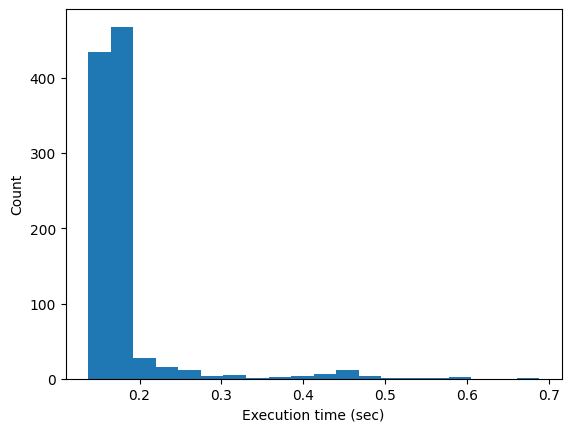
count 1000.000000
mean 0.178465 sec
std 0.058125 sec
min 0.137314 sec
25% 0.161333 sec
50% 0.165919 sec
75% 0.171736 sec
max 0.687994 sec