Decorator-based Python Integration
Integrate Langfuse Tracing into your LLM applications with the Langfuse Python SDK using the @observe() decorator.
The SDK supports both synchronous and asynchronous functions, automatically handling traces, spans, and generations, along with key execution details like inputs, outputs and timings. This setup allows you to concentrate on developing high-quality applications while benefitting from observability insights with minimal code. The decorator is fully interoperable with our main integrations (more on this below): OpenAI, Langchain, LlamaIndex.
See the reference (opens in a new tab) for a comprehensive list of all available parameters and methods.
Want more control over the traces logged to Langfuse? Check out the low-level Python SDK.
Overview
Example
Simple example (decorator + openai integration)
from langfuse.decorators import observe
from langfuse.openai import openai # OpenAI integration
@observe()
def story():
return openai.chat.completions.create(
model="gpt-3.5-turbo",
max_tokens=100,
messages=[
{"role": "system", "content": "You are a great storyteller."},
{"role": "user", "content": "Once upon a time in a galaxy far, far away..."}
],
).choices[0].message.content
@observe()
def main():
return story()
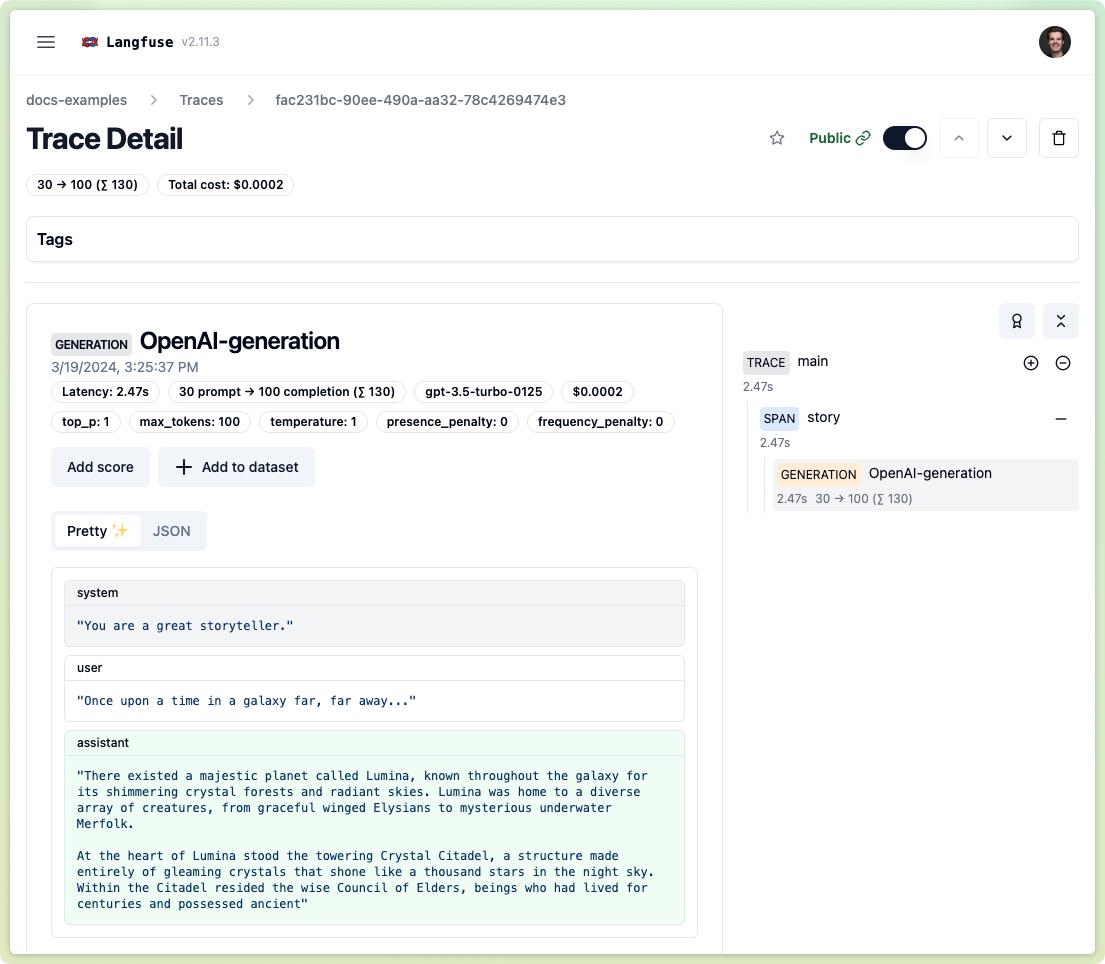
main()Trace in Langfuse (public link (opens in a new tab))
Installation & setup
Install the Langfuse Python SDK

pip install langfuseAdd Langfuse API keys
If you haven't done so yet, sign up to Langfuse (opens in a new tab) and obtain your API keys from the project settings. Alternatively, you can also run Langfuse locally or self-host.
import os
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU region
# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US regionAdd the Langfuse decorator
Import the @observe() decorator and apply it to the functions you want to trace. By default it captures:
- nesting via context vars
- timings/durations
- function name
- args and kwargs as input dict
- returned values as output
The decorator will automatically create a trace for the top-level function and spans for any nested functions. Learn more about the tracing data model here.
from langfuse.decorators import observe
@observe()
def fn():
pass
@observe()
def main():
fn()
main()Done! ✨ Read on to learn how to capture additional information, LLM calls, and more with Langfuse Python decorators.
In a short-lived environment like AWS Lambda, make sure to call flush() before the
function terminates to avoid losing events. Learn more.
from langfuse.decorators import observe, langfuse_context
@observe()
def main():
print("Hello, from the main function!")
main()
langfuse_context.flush()Decorator arguments
See SDK reference (opens in a new tab) for full details.
Log any LLM call
In addition to the native intgerations with LangChain, LlamaIndex, and OpenAI (details below), you can log any LLM call by decorating it with @observe(as_type="generation"). Important: Make sure the as_type="generation" decorated function is called inside another @observe()-decorated function for it to have a top-level trace.
Optionally, you can parse some of the arguments to the LLM call and pass them to langfuse_context.update_current_observation to enrich the trace.
import anthropic
anthopic_client = anthropic.Anthropic()
# Wrap LLM function with decorator
@observe(as_type="generation")
def anthropic_completion(**kwargs):
# optional, extract some fields from kwargs
kwargs_clone = kwargs.copy()
input = kwargs_clone.pop('messages', None)
model = kwargs_clone.pop('model', None)
langfuse_context.update_current_observation(
input=input,
model=model,
metadata=kwargs_clone
)
# return result
return anthopic_client.messages.create(**kwargs).content[0].text
@observe()
def main():
return anthropic_completion(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[
{"role": "user", "content": "Hello, Claude"}
]
)
main()Capturing of input/output
By default, the @observe() decorator captures the input arguments and output results of the function.
You can disable this behavior by setting the capture_input and capture_output parameters to False.
from langfuse.decorators import observe
@observe(capture_input=False, capture_output=False)
def fn(secret_arg):
return "super secret output"
fn("my secret arg")You can manually set the input and output of the observation using langfuse_context.update_current_observation (details below).
from langfuse.decorators import langfuse_context, observe
@observe(capture_input=False, capture_output=False)
def fn(secret_arg):
langfuse_context.update_current_observation(
input="sanitized input", # any serializable object
output="sanitized output", # any serializable object
)
return "super secret output"
fn("my secret arg")This will result in a trace with only sanitized input and output, and no actual function arguments or return values.
Decorator context
Use the langfuse_context object to interact with the decorator context. This object is a thread-local singleton and can be accessed from anywhere within the function context.
Add additional attributes to the trace and observations
In addition to the attributes automatically captured by the decorator, you can add others to use the full features of Langfuse.
Please read the reference for more details on available parameters:
langfuse_context.update_current_observation(reference (opens in a new tab)): Update the trace/span of the current function scopelangfuse_context.update_current_trace(reference (opens in a new tab)): Update the trace itself, can also be called within any deeply nested span within the trace
Below is an example demonstrating how to enrich traces and observations with custom parameters:
from langfuse.decorators import langfuse_context, observe
@observe()
def deeply_nested_fn():
# Enrich the current observation with a custom name, input, and output
# All of these parameters override the default values captured by the decorator
langfuse_context.update_current_observation(
name="Deeply nested LLM call",
input="Ping?",
output="Pong!"
)
# Updates the trace, overriding the default trace name `main` (function name)
langfuse_context.update_current_trace(
name="Trace name set from deeply_nested_llm_call",
session_id="1234",
user_id="5678",
tags=["tag1", "tag2"],
public=True
)
return "output" # This output will not be captured as we have overridden it
@observe()
def nested_fn():
# Update the current span with a custom name and level
# Overrides the default span name
langfuse_context.update_current_observation(
name="Nested Span",
level="WARNING"
)
deeply_nested_fn()
@observe()
def main():
# This will be the trace as it is the highest level function
nested_fn()
# Execute the main function to generate the enriched trace
main()Get trace URL
You can get the URL of the current trace using langfuse_context.get_current_trace_url(). Works anywhere within the function context, also in deeply nested functions.
from langfuse.decorators import langfuse_context, observe
@observe()
def main():
print(langfuse_context.get_current_trace_url())
main()Trace/observation IDs
By default, Langfuse assigns random IDs to all logged events.
Get trace and observation IDs
You can access the current trace and observation IDs from the langfuse_context object.
from langfuse.decorators import langfuse_context, observe
@observe()
def fn():
print(langfuse_context.get_current_trace_id())
print(langfuse_context.get_current_observation_id())
fn()Set custom IDs
If you have your own unique ID (e.g. messageId, traceId, correlationId), you can easily set those as trace or observation IDs for effective lookups in Langfuse. Just pass the langfuse_observation_id keyword argument to the decorated function.
from langfuse.decorators import langfuse_context, observe
@observe()
def process_user_request(user_id, request_data, **kwargs):
# Function logic here
pass
@observe(**kwargs)
def main():
process_user_request(
"user_id",
"request",
langfuse_observation_id="my-custom-request-id",
)
main(langfuse_observation_id="my-custom-request-id")Interoperability with framework integrations
The decorator is fully interoperable with our main integrations: OpenAI, Langchain, LlamaIndex. Thereby you can easily trace and evaluate functions that use (a combination of) these integrations.
OpenAI
The drop-in OpenAI SDK integration is fully compatible with the @observe() decorator. It automatically adds a generation observation to the trace within the current context.
from langfuse.decorators import observe
from langfuse.openai import openai
@observe()
def story():
return openai.chat.completions.create(
model="gpt-3.5-turbo",
max_tokens=100,
messages=[
{"role": "system", "content": "You are a great storyteller."},
{"role": "user", "content": "Once upon a time in a galaxy far, far away..."}
],
).choices[0].message.content
@observe()
def main():
return story()
main()LangChain
The native LangChain integration is fully compatible with the @observe() decorator. It automatically adds a generation to the trace within the current context.
langfuse_context.get_current_langchain_handler() exposes a callback handler scoped to the current trace context. Pass it to subsequent runs to your LangChain application to get full tracing within the scope of the current trace.
from operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
from langfuse.decorators import observe
prompt = ChatPromptTemplate.from_template("what is the city {person} is from?")
model = ChatOpenAI()
chain = prompt | model | StrOutputParser()
@observe()
def langchain_fn(person: str):
# Get Langchain Callback Handler scoped to the current trace context
langfuse_handler = langfuse_context.get_current_langchain_handler()
# Pass handler to invoke of your langchain chain/agent
chain.invoke({"person": person}, config={"callbacks":[langfuse_handler]})
langchain_fn("John Doe")LlamaIndex
The LlamaIndex integration is fully compatible with the @observe() decorator. It automatically adds a generation to the trace within the current context.
Via Settings.callback_manager you can configure the callback to use for tracing of the subsequent LlamaIndex executions. langfuse_context.get_current_llama_index_handler() exposes a callback handler scoped to the current trace context.
from langfuse.decorators import langfuse_context, observe
from llama_index.core import Document, VectorStoreIndex
from llama_index.core import Settings
from llama_index.core.callbacks import CallbackManager
doc1 = Document(text="""
Maxwell "Max" Silverstein, a lauded movie director, screenwriter, and producer, was born on October 25, 1978, in Boston, Massachusetts. A film enthusiast from a young age, his journey began with home movies shot on a Super 8 camera. His passion led him to the University of Southern California (USC), majoring in Film Production. Eventually, he started his career as an assistant director at Paramount Pictures. Silverstein's directorial debut, “Doors Unseen,” a psychological thriller, earned him recognition at the Sundance Film Festival and marked the beginning of a successful directing career.
""")
doc2 = Document(text="""
Throughout his career, Silverstein has been celebrated for his diverse range of filmography and unique narrative technique. He masterfully blends suspense, human emotion, and subtle humor in his storylines. Among his notable works are "Fleeting Echoes," "Halcyon Dusk," and the Academy Award-winning sci-fi epic, "Event Horizon's Brink." His contribution to cinema revolves around examining human nature, the complexity of relationships, and probing reality and perception. Off-camera, he is a dedicated philanthropist living in Los Angeles with his wife and two children.
""")
@observe()
def llama_index_fn(question: str):
# Set callback manager for LlamaIndex, will apply to all LlamaIndex executions in this function
langfuse_handler = langfuse_context.get_current_llama_index_handler()
Settings.callback_manager = CallbackManager([langfuse_handler])
# Run application
index = VectorStoreIndex.from_documents([doc1,doc2])
response = index.as_query_engine().query(question)
return responseAdding scores
Scores (opens in a new tab) are used to evaluate single observations or entire traces. They can created manually via the Langfuse UI or via the SDKs.
| Parameter | Type | Optional | Description |
|---|---|---|---|
name | string | no | Identifier of the score. |
value | number | no | The value of the score. Can be any number, often standardized to 0..1 |
comment | string | yes | Additional context/explanation of the score. |
You can attach a score to the current observation context by calling langfuse_context.score_current_observation. You can also score the entire trace from anywhere inside the nesting hierarchy by calling langfuse_context.score_current_trace:
from langfuse.decorators import langfuse_context, observe
# This will create a new span under the trace
@observe()
def nested_span():
langfuse_context.score_current_observation(
name="feedback-on-span",
value=1,
comment="I like how personalized the response is",
)
langfuse_context.score_current_trace(
name="feedback-on-trace",
value=1,
comment="I like how personalized the response is",
)
# This will create a new trace
@observe()
def main():
nested_span()
main()Additional configuration
Flush observations
The Langfuse SDK executes network requests in the background on a separate thread for better performance of your application. This can lead to lost events in short lived environments such as AWS Lambda functions when the Python process is terminated before the SDK sent all events to our backend.
To avoid this, ensure that the langfuse_context.flush() method is called before termination. This method is waiting for all tasks to have completed, hence it is blocking.
Debug mode
Enable debug mode to get verbose logs. Set the debug mode via the environment variable LANGFUSE_DEBUG=True.
Authentication check
Use langfuse_context.auth_check() to verify that your host and API credentials are valid. This operation is blocking and is not recommended for production use.
Limitations
Known limitations:
- When run in
ThreadPoolExecutor, separate traces for each thread are created. - Large input/output data can lead to performance issues. We recommend disabling capturing input/output for these methods and manually add the relevant information via
langfuse_context.update_current_observation.
API reference
See the Python SDK API reference (opens in a new tab) for more details.